prisma vs n+1
Hermaeus Mora ·
다음과 같은 테이블이 있다고 하자.
model User {
id String @id @default(uuid())
email String @unique
posts Post[]
}
model Post {
id String @id @default(uuid())
userId String
title String @db.VarChar(1024)
}아래 코드는 JPA에서 N+1를 발생시키는 대표적인 쿼리이다.
prisma.user.findMany({
select: {
id: true,
email: true,
posts: {
select: {
id: true,
title: true
}
}
},
take: 10
});JPA에서는 아래의 구문을 다음 순서대로 실행한다.
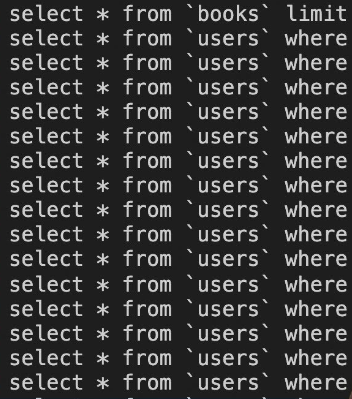
- 유저 테이블에서 유저 10명을 쿼리
- 가져온 유저 인스턴스에 포스트 정보가 없으므로 포스트 테이블에서 유저 id로 쿼리 10번 실행 (eagar fetch인 경우)
N+1문제를 회피하는 여러 방법 중 Batch Size가 있는데, 가져온 id값 만큼의 쿼리를 생성하는 대신 id값들을 전부 in절에 때려 박는 방식이다. 즉 11번 실행될 것을 2번만 실행시키는 것.
prisma의 쿼리 이벤트를 출력해보면 Batch size를 사용하여 N+1문제를 회피하고 있음을 알 수 있다.

추가적으로, prisma는 5.10.0버전부터 relationJoins라는 신규 쿼리 옵션을 지원하는데,
해당 옵션을 사용하면 위의 Batch size 방식이 아닌 단일 쿼리를 사용한다.

위 쿼리를 포매팅하면 다음과 같이 서브쿼리를 사용하는 것을 알 수 있다.
SELECT
`t1`.`id`,
`t1`.`email`,
(
SELECT
COALESCE(
JSON_ARRAYAGG (`__prisma_data__`),
CONVERT(\'[]\', JSON)
) AS `__prisma_data__`
FROM
(
SELECT
`t4`.`__prisma_data__`
FROM
(
SELECT
JSON_OBJECT (\'id\', `t3`.`id`, \'title\', `t3`.`title`) AS `__prisma_data__`
FROM
(
SELECT
`t2`.*
FROM
`Post` AS `t2`
WHERE
`t1`.`id` = `t2`.`userId` /* root select */
) AS `t3` /* inner select */
) AS `t4` /* middle select */
) AS `t5` /* outer select */
) AS `posts`
FROM
`User` AS `t1`
ORDER BY
`t1`.`createdAt` DESC
LIMIT
10