네트워크
Hermaeus Mora ·
웹 통신의 큰 흐름: https://lofies.com/ 을 접속할 때 일어나는 일
브라우저에 lofies.com을 입력한다고 하자. 그럼 브라우저는 os 제공 함수 gethostbyname을 호출한다. 이 함수는 etc/host.conf 파일을 읽고 resolve 방식을 결정한다. 만일 참조 순서가 호스트 파일 -> 네임서버 순서(order hosts, bind) 이고 etc/hosts에 해당하는 ip-도메인 쌍이 있다면 ip는 즉시 반환된다. 없다면 로컬 서버의 dns resolver가etc/resolv.conf 파일에서 dns ip를 참조한다. dns는 보통 ISP(인터넷 제공업체, skt등) ip로 설정된 경우가 많다. 예를 들어 여기에 ip 8.8.8.8이 등록되어 있다면 구글 dns가 resolver가 되며, 루트 서버 및 tld 서버 등에 도메인 주소를 질의한다. 구글 dns의 재귀 호출 예시는 다음과 같다.
- 루트 서버 13개의 주소(dns내에 저장되어 있음)에 순차적으로 도메인을 질의
- 루트 서버 f.root-servers.net.가 com.과 tld 서버 목록을 응답
- tld 서버 목록에 순차적으로 도메인 을 질의
- tld 서버 f.gtld-servers.net.가 lofies.com.과 aws 네임 서버 목록을 응답
- aws 네임 서버 목록에 도메인을 질의
- aws 네임 서버 ns-148.awsdns-18.com.가 도메인의 A레코드와 다른 3개의 네임서버 레코드를 응답
재귀 호출이 끝나면 구글 dns는 A레코드를 반환하고, gethostbyname함수도 즉시 브라우저에 해당 ip를 반환한다. 이 과정은 dig lofies.com (8.8.8.8) +trace 명령으로 상세히 조회할 수 있다.
TCP와 UDP의 차이점에 대해서 설명해보세요.
TCP는 흐름 제어와, 혼잡 제어를 통해 데이터의 손실을 최소화하고 데이터의 순서를 보장하지만 그만큼 속도가 저하되고, 패킷의 사이즈가 크다. UDP는 데이터의 손실을 감안하고 데이터의 순서를 보장하지 않지만 그만큼 속도가 빠르며 패킷의 사이즈가 적다.
흐름 제어:
핸드쉐이크 과정이 끝나면 수신자 윈도우(RWND, receiver window)를 응답받는다. 이는 수신 가능한 버퍼의 사이즈를 의미한다. 그러나 송신 측이 이를 바로 사용하진 않고, 혼잡 제어 정책에 따른 혼잡 윈도우(CWND, Congestion window) 사이즈와 비교하여 더 작은 값을 사용한다.
이 윈도우를 사용하는 흐름 제어를 슬라이딩 윈도우라고 한다(스탑 앤 웨이트는 너무 비효율적이므로 여기서 다루지 않는다).
보내야 할 데이터의 크기가 100byte라고 하자. 또 윈도우 사이즈가 50byte라고 하자.
슬라이딩 윈도우에서 송신 측은 응답 대기 없이 150byte를 연속해서 송신하려고 시도한다.
송신 측이 130byte를 보내고, 수신 측이 버퍼에서 송신받은 130byte를 처리하고 ACK 30을 응답하면50byte -> 31
윈도우의 위치는 180byte로 슬라이딩한다.
또 송신 측이 3150byte를 보내고, 수신 측이 버퍼에서 송신받은 3150byte를 처리하고 ACK 20을 응답하면
윈도우의 위치는 3180byte -> 51~100byte로 또 슬라이딩한다.
이처럼 응답을 기다리는 동안 연속적으로 데이터를 전송하므로 스탑 앤 웨이트보다 훨씬 더 효율적이다. 따라서 현재 거의 모든 흐름 제어는 이 슬라이딩 윈도우 방식을 사용하고 있다.
혼잡 제어:
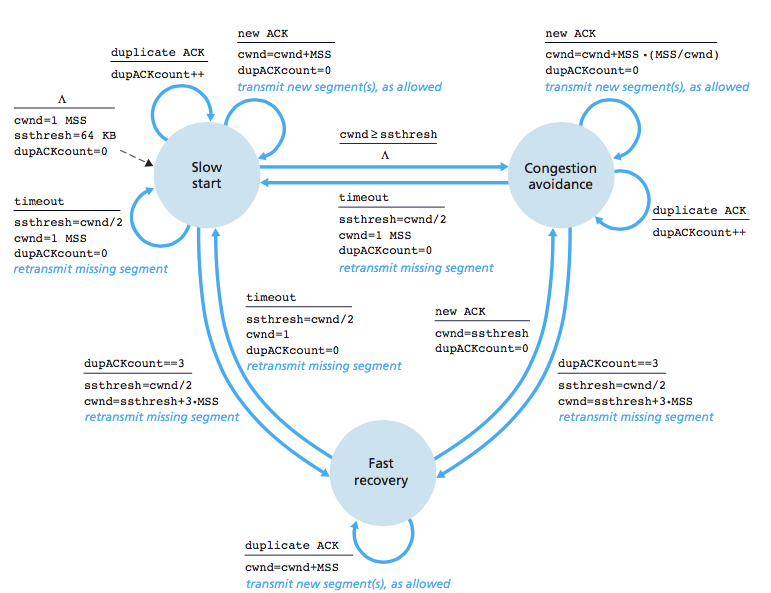
혼잡 제어 정책에 따라 혼잡 윈도우 사이즈가 정해진다고 했다. 혼잡 윈도우(cwnd)는 1로 초기화되고, 단위는 MSS (대략 1450byte)이다. 혼잡 제어는 여러 상태값을 가진다. 그 중에는 슬로우 스타트, 혼잡 회피(=AIMD, Additive Increase/Multicative Decrease), 빠른 회복(Fast Recovery)이 있다.
슬로우 스타트 상태에서 cwnd는 ACK 수신 시 마다 1씩 증가한다. 즉 지수적으로 증가한다.
혼잡 회피 상태, AIMD는 직역하면 합-증가/곱-감소인데, ACK 수신 시 마다 씩 증가한다. 즉 한 rtt가 돌아야 1씩 증가한다.
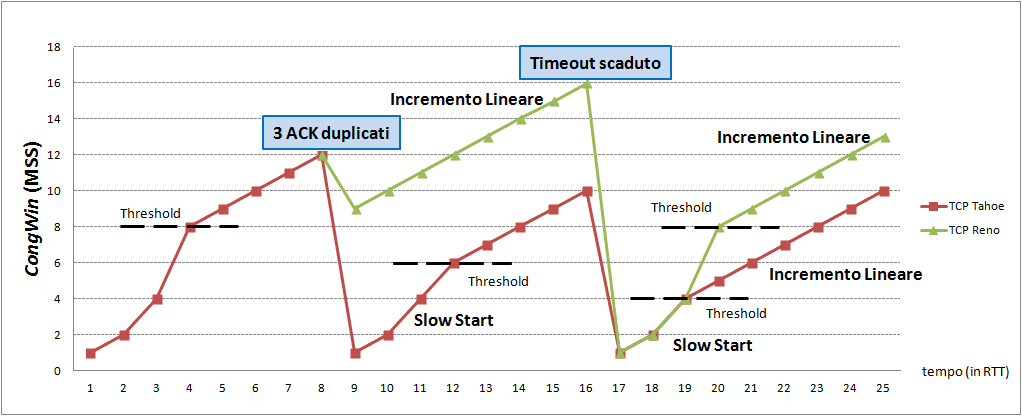
대표적인 혼잡 제어 정책에는 Tahoe와 Reno가 있다. 두 정책의 차이점은 Tahoe는 빠른 회복 상태가 없다는 것이다.
Tahoe
Tahoe는 슬로우 스타트 방식을 쓰다가 중복 ACK가 3번 발생하거나 Timeout이 발생하면 현재의 cwnd의 절반을 ssthresh(slow start threshold)로 지정한다. 그리고 cwnd값을 1로 바꿔서 다시 슬로우 스타트 방식을 사용하고, 그 후 증가하다가 ssthresh에 도달하면 혼잡 회피 상태로 전환한다. 이 방식은 안전하지만 cwnd값이 1로 초기화되어 다시 임계점에 도달하기까지의 시간이 지연되게 된다.
Reno
Reno는 Tahoe의 단점을 보완하기 위해 빠른 회복(Fast Recovery)상태를 사용한다. Tahoe처럼 슬로우 스타트를 사용하다가 중복 ACK가 3번 발생하면 빠른 회복 상태로 전환한다. 이때 현재의 cwnd의 절반을 ssthresh(slow start threshold)로 지정하고, 현재의 cwnd를 ssthresh + 3MSS로 설정한다. 빠른 회복 상태에서 새로운 ACK를 응답받을 경우, 혼잡 회피 상태로 전환한다. 만약 중복 ACK 3번이 아니라 Timeout이 발생하면, Tahoe와 동일하게 동작한다.
TCP 3, 4 way handshake에 대해서 설명해보세요.
3 way handshake
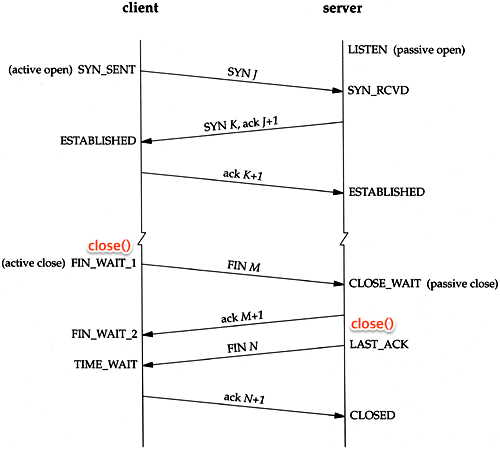
송신측와 수신측이 주고받는 세그먼트는 기본적으로 순서가 보장되지 않는다. 그래서 TCP는 시퀀스 넘버(Sequence Number)를 사용하여 이 순서를 보장하는데, 가령 송신측에서 시퀀스 넘버가 2800인 1400byte 세그먼트를 보내면(SEQ 2800) 수신측은 해당 세그먼트를 확인했다는 응답을 보낸다(ACK 4200) 이때 응답 세그먼트의 ACK 넘버가 의미하는 바는 2800byte부터 4199byte까지 1400byte를 읽어들였고 4200번째 byte를 받겠다는 것이다. 만약 다음 요청이 4200번째 byte가 아니면 수신측은 계속해서 ACK 4200을 응답하며 송신측도 이에 따라 응답한다. 이것이 TCP가 세그먼트의 순서를 보장하는 방법인데, 시퀀스 넘버를 2800부터 시작하는 것으로 예시를 들었지만 실제로 초기 시퀀스 넘버(ISN)는 랜덤한 32비트 정수이다. 시퀀스 넘버가 랜덤하기 때문에 송신측과 수신측은 서로의 시퀀스 넘버를 모르는 상태이므로, 이를 동기화하기 위해 서로의 시퀀스 넘버를 주고 받음으로써 TCP 연결을 시작한다. 이 순서는 다음과 같다(J, K는 랜덤).
- 송신측이 SYN J로 연결 요청. SYN_SENT(응답 대기) 상태가 됨
- 수신측이 요청을 받고 ACK J+1(요청 응답)과 SYN K(연결 요청)를 응답. SYN_RCVD(응답 대기) 상태가 됨.
- 송신측이 응답을 받고 ESTABLISHED(연결 수립) 상태가 됨. ACK K+1으로 요청에 응답. 수신측도 응답을 받고 ESTABLISHED(연결 수립) 상태가 됨.
4 way handshake
핸드셰이크로 연결을 수립했으므로 데이터의 전송이 끝나면 연결을 해제해야 한다. 그렇지 않으면 연결에 필요한 소켓이 제때 제거되지 않아 리소스가 낭비될 것이다. 4 way handshake의 순서는 다음과 같다(M, N은 랜덤).
- 송신측이 FIN M으로 연결 종료 요청. FIN_WAIT(종료 대기) 상태가 됨
- 수신측이 요청을 받고 ACK M+1으로 요청 응답. CLOSE_WAIT(종료 대기) 상태가 됨. 송신측은 응답 받은 이후에도 FIN_WAIT(종료 대기)
- 수신측이 CLOSE 준비가 완료된 이후 FIN N으로 연결 종료 요청. LAST_ACK(응답 대기) 상태가 됨. 송신측은 요청을 받고 TIME_WAIT(잉여 대기) 상태가 되며, 일정 시간(디폴트 240초)동안 잉여 패킷을 기다림(종료된 이후엔 늦게 도착한 패킷이 유실되므로).
- 송신측이 TIME_WAIT 상태를 벗어나면 ACK N+1으로 요청 응답 후 연결 종료. 수신측도 응답을 받고 연결 종료.
HTTP와 HTTPS의 차이점에 대해서 설명해보세요.
HTTP와 HTTPS의 차이점은 TLS 암호화 적용 여부이다. TLS 암호화는 HTTP에 존재하지 않는 다음 3가지 주요 목표를 달성한다.
암호화: 제3자로부터 전송되는 데이터를 숨김
HTTP 프로토콜은 평문을 전송하므로 패킷이 같은 네트워크로 브로드캐스트 되는 경우 같은 네트워크 이용자에게 평문이 그대로 노출된다.
인증: 정보를 교환하는 당사자가 요청된 당사자임을 보장
클라이언트가 통신하는 HTTP서버가 요청하는 당사자가 아닐 가능성이 존재한다. (피싱 사이트)
무결성: 데이터가 위조되거나 변조되지 않았음을 보장
HTTP 패킷은 중간자 공격에 의해 위조될 수 있으며, DNS 쿼리가 하이재킹당하는 경우 클라이언트는 악의적인 사이트로 이동될 수 있다.
HTTPS에 대해서 설명하고 SSL Handshake에 대해서 설명해보세요.
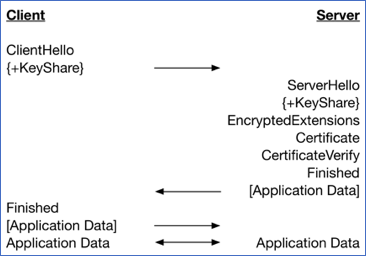
HTTP 프로토콜에 TLS 암호화(TLS 1.3 기준)를 적용하기 위해서는 비대칭 키 페어, 신뢰할 수 있는 인증 기관(CA)으로부터 발급받은 TLS 인증서가 필요하며, TLS 인증서는 비대칭 키 페어의 공개 키와 인증서 소유주의 정보 등을 포함해야 한다. 서버에 TLS 암호화가 적용되어 있고, 클라이언트가 서버로 HTTPS 요청을 보내거나, 브라우저가 DoH(DNS Over HTTPS) 요청을 보내는 경우, TCP 3 way handshake가 성공한 이후 TLS Handshake가 발생하며, 순서는 다음과 같다(클라이언트 TLS 인증은 생략한다).
-
클라이언트가 서버로 ClientHello. 이 요청은 브라우저가 사용하는 TLS 버전 정보, 브라우저가 지원하는 Cipher Suite, 클라이언트 난수(PRNG) 등을 포함한다.
-
서버가 클라이언트로 ServerHello. 이 응답은 서버가 지원하는 Cipher Suite, TLS 인증서, 서버 난수(PRNG) 등을 포함한다.
-
클라이언트는 서버로부터 받은 TLS 인증서의 CSR(Certificate Signing Request, 인증서 서명 요청)로부터 믿을수 있는 인증 기관(Trusted CA)의 인증서인지 확인한다. 인증 기관이 식별되지 않으면 핸드셰이크는 실패한다. Trusted CA인 경우, 인증서를 파싱한다. 이때 인증서는 CA의 개인키로 암호화된 CSR을 포함하고, 브라우저가 --대다수의 브라우저는 Trusted CA의 공개키를 가지고 있으므로-- 이를 CA의 공개키로 복호화에 성공한다면 --CA의 개인키로 암호화한 CSR은 CA의 공개키로밖에 복호화할수 없으므로-- TLS 인증에 성공한다. TLS 인증에 성공하면 클라이언트는 ECDHE(Elliptic Curve Diffie-Hellman Ephermeral) 공유 키를 생성하고 이를 클라이언트 난수, 서버 난수와 조합하여 대칭키를 생성한다. 그리고 ECDHE 공유 키를 인증서에 포함된 서버의 공개키로 암호화하고, 요청 전문을 대칭키로 암호화하여 서버 측으로 전달한다. 서버가 ECDHE 공유 키를 받고 이를 개인키로 복호화에 성공하면, 같은 방식으로 대칭 키를 생성한다. 이 시점부터 클라이언트와 서버가 서로 대칭키를 알고 있으므로, 모든 요청 및 응답은 암호화되며, TLS 핸드셰이크가 종료된다.
GET과 POST의 차이점에 대해서 설명해보세요.
RESTful에서, GET, PUT, DELETE는 일반적으로 멱등성을 가지며, POST는 멱등성을 가지지 않는다.
멱등성(RESTful) 동일한 요청을 한 번 보내는 것과 여러 번 보내는 것이 결과적으로 동일한 효과를 지니며, 서버의 상태에도 동일한 영향을 미치는 성질
예를 들어 보자. 일반적으로 POST는 멱등성을 가지지 않는다고 했다. 그럼 다음 API는 멱등성을 가지지 않는가?
POST table/1/row // Returns 201, add a 1nd row
POST table/1/row // Returns 201, add a 2nd row
POST table/1/row // Returns 201, add a 3nd row그렇지 않다. 3번의 요청 모두 동일하게 table 1에 row를 생성하는 효과를 지니기 때문이다.
POST table // Returns 201, `table 2` has created.
POST table // Returns 409, `table 2` already exists.위의 API는 멱등성을 가지지 않는다. 오직 첫번째 요청만 새 테이블을 생성하는 효과를 지닌다.
DELETE table/1/row/1 // Returns 200, `row 1` is deleted.
DELETE table/1/row/1 // Returns 404, `row 1` is not found.위의 API는 멱등성을 가진다. 모든 요청은 결과적으로 row 1을 삭제하는 효과를 지니며, 결과적으로 서버의 상태도 동일하다.
GET은 일반적으로 멱등성을 가지지만 GET이 부수 효과를 가지고 있다면 멱등성을 가진다고 말할 수 없다.
예를 들어 GET post 요청 시 post의 조회수를 1 증가시킨다고 한다면, 결과적으로 서버의 상태가 계속해서 변하게 되므로, 멱등성을 가진다고 말할 수 없다. 이 경우에는 클라이언트가 두 번의 API 요청을 보내는 것이 바람직하다.
또한 같은 payload로 PUT, PATCH 메서드를 여러번 호출하는 경우 updatedAt이 계속 변경된다고 하면, 마찬가지로 멱등성을 가진다고 말할 수 없다.
HTTP 메서드와 이것이 하는 역할에 대해서 설명해보세요.
HTTP 메서드는 주어진 리소스에 수행하길 원하는 행동을 나타낸다.
| 메서드 | 행위 | 멱등적 | 안전함 |
|---|---|---|---|
| GET | 특정 리소스 요청 | ✅ | ✅ |
| HEAD | 특정 리소스의 본문을 제외하고 요청 | ✅ | ✅ |
| OPTIONS | 특정 리소스의 통신을 설정 | ✅ | ✅ |
| PATCH | 특정 리소스를 부분 수정 | ✅ | ✅ |
| PUT | 특정 리소스를 요청 payload로 교체 | ✅ | ❌ |
| DELETE | 특정 리소스를 삭제 | ✅ | ❌ |
| POST | 특정 리소스에 엔티티를 제출 | ❌ | ❌ |
RESTful이란 무엇이며, 이것에 대해서 아는대로 설명해보세요.
REST 아키텍처는 API(Application Programming Interface)의 작동 방식에 대해 조건을 부과하는 아키텍처이며, RESTFul API는 REST 아키텍처를 따르는 API를 말한다. REST 아키텍처가 API의 작동 방식에 부여하는 조건은 다음과 같다.
균일한 인터페이스
요청은 리소스를 식별할 수 있어야 하므로, 균일한 리소스 식별자를 사용한다. 예를 들어, 어떠한 리소스의 URL이 분류 별로 슬래시(/)를 나누어 식별된다면, 다른 모든 리소스도 그러해야 한다. 또한 서버는 적절한 메타데이터를 응답함으로써 리소스를 충분히 식별 가능하도록 해야 한다. JSON 포맷으로 응답한다고 했을 경우, 모든 값들은 적절한 키에 의해 식별되어야 한다.
무상태
서버는 이전의 모든 요청과 독립적으로 모든 요청을 처리해야 한다. 예를 들어, 서버 자체에 해시맵을 두어 이전의 요청을 캐싱하면 안된다.
계층화
서버는 계층적인 구조를 지녀야 하며, 서버의 여러 기능은 각각 서버의 다른 계층, 다른 서버, 다른 중계자에서 실행될 수 있다. 이렇게 나뉘어진 계층은 클라이언트에게는 단일 계층으로 보여야 한다. 예를 들어 서버는 인증 서버와 데이터베이스 계층을 서버에서 분리시킬 수 있다.
캐시 가능
서버의 응답은 때때로 캐싱될 수 있으며, 서버는 캐시 가능 여부를 응답에 포함함으로써 캐싱을 제어해야 한다.
REST 아키텍처의 제약조건으로 인해 서버와 클라이언트는 서로 독립적으로 분리될 수 있으며, 서버는 무상태이기 때문에 수평적으로 확장할 수 있고, 계층적이기 때문에 유연하게 변경될 수 있고 단일 장애점을 제거할 수 있다.
CORS란 무엇이며 이것에 대해서 설명해보세요.
CORS(Cross-Origin Resource Sharing, 교차 출처 리소스 공유)란 브라우저가 자신의 출처가 아닌 다른 출처로부터 자원을 로딩하도록 하는 매커니즘을 의미한다.
여기서 말하는 자신의 출처(same-origin)란 프로토콜, 호스트, 포트가 모두 일치하는 도메인이며 이중 하나라도 다를 경우 브라우저는 이를 다른 도메인(cross-origin)으로 판단한다.
브라우저가 다른 출처로 요청할 때, 다음 3가지 조건 중 하나라도 만족하지 않는 경우, 본 요청에 앞서 preflight 요청을 발행한다.
- GET, HEAD, POST, 요청인 경우
- 헤더에 CORS-safelisted request header(
Accept,Accept-Language,Content-Language,Content-Type,Range) 만을 포함할 경우 - Content-Type이
application/x-www-form-urlencoded,multipart/form-data,text/plain중 하나인 경우
preflight 요청의 메서드는 options 이며, 서버는 해당 요청에 대한 응답으로 본문을 제외한 헤더를 응답한다.
서버는 이 응답 헤더에 교차 출처 리소스 공유 정책 헤더를 포함해야 한다.
Access-Control-Allow-Origin
교차 출처를 허용할 클라이언트의 URL을 나열한다. 모든 클라이언트의 교차 출처를 허용하기 위해서는 Asterisk(\*)를 기입한다. 요청 헤더의 Origin 값이 허용된 URL이 아닌 경우 브라우저는 CORS 에러를 반환한다.
Access-Control-Allow-Header
교차 출처를 허용할 헤더를 나열한다. 요청 헤더가 허용된 헤더가 아닌 경우 브라우저는 CORS 에러를 반환한다.
Access-Control-Allow-Method
교차 출처를 허용할 요청 메서드를 나열한다. 요청 메서드가 허용된 메서드가 아닌 경우 브라우저는 CORS 에러를 반환한다.
Access-Control-Allow-Credentials
교차 출처로부터의 요청이 credentials을 포함해도 되는지를 설정한다. credentials란 쿠키, 클라이언트 TLS 인증서, username과 password를 포함하는 인증 헤더를 말한다. 서버가 이 응답 헤더를 true로 설정하기 위해서는 Access-Control-Allow-Origin 헤더가 Asterisk(\*)여서는 안된다, 이 응답 헤더 값이 true가 아니고 클라이언트 요청에 credentials이 포함되어 있는 경우, 브라우저는 CORS 에러를 반환한다.
OSI7계층과 그 존재 이유, TCP/IP 4계층에 대해 설명해보세요,
TCP/IP 4계층 관점에서 서버의 클라이언트 요청에 대한 응답 데이터의 흐름을 예를 들어 보자. 응용 계층은 http 프로토콜을 사용하는 응용 프로그램을 포함하며 이 예제에서는 서버가 응용 계층에 해당된다. 서버는 os의 socket() 시스템 콜(System call)에 소켓 스트림(TCP)을 매개변수로 전달함으로써 TCP소켓 fd(File Descriptor)를 반환받고 fd.bind() 시스템 콜을 통해 서버의 ip 및 포트를 매핑한다. 그리고 fd.listen() 시스템 콜을 통해 listen queue 및 backlog를 생성한다. 서버가 listen() 상태에 들어가면 클라이언트의 요청은 서버와 핸드셰이크를 진행한다. 핸드셰이크 과정에서 클라이언트가 서버의 SYN 패킷에 응답하면 서버는 ESTABLISHED socket을 생성하고 생성된 소켓이 listen queue에 저장된다. 만약 클라이언트가 서버의 SYN 패킷에 응답하지 않는다면 backlog로 저장된다. SYN_Flooding 공격을 방지하기 위해서는 backlog 사이즈를 적절하게 조정해야 한다. 이후 서버가 accpect() 시스템 콜을 사용하면 listen queue의 소켓을 차례대로 읽는다. 이 소켓은 L4 전송 계층에서 로드밸런싱된 패킷이 들어오는 수신 버퍼, 전송 계층으로 데이터를 내보내는 송신 버퍼로 구성되어 있다. 서버는 수신 버퍼의 데이터를 recv()로 읽고 응답을 직렬화하여 송신 버퍼에 send()한다. TCP 스택은 다시 송신 버퍼에 들어간 데이터에 시퀀스 넘버 등의 TCP 헤더를 붙여서 세그먼트를 만들고, 이는 TCP 상태 머신에 의해 적정한 시간이 지나면 인터넷 계층으로 이동한다. 이 계층에서도 TCP 스택이 세그먼트에 출발지 IP와 목적지 IP 등의 IP헤더를 붙여 패킷을 만든다. 이렇게 만들어진 패킷이 NIC까지 도달하면 NIC는 패킷을 이더넷 프레임 형태로 변환하여 게이트웨이 (혹은 라우터)로 전달하고, 라우터는 라우팅 테이블을 참조하거나 최적 경로를 계산하여 패킷을 목적지 IP까지 전달한다.
웹 서버 소프트웨어(Apache, Nginx)는 OSI 7계층 중 어디서 작동하는지 설명해보세요.
웹 서버는 HTTP 프로토콜을 사용하여 클라이언트에게 정적 리소스를 제공하는 서버를 말하며 이는 응용 계층에서 작동한다.
웹 서버 소프트웨어(Apache, Nginx)의 서버 간 라우팅 기능은 OSI 7계층 중 어디서 작동하는지 설명해보세요.
Apache Http Server, Nginx 모두 프록시 및 리버스 프록시, 로드 밸런싱 기능을 제공한다.
<Proxy \"balancer://mycluster\">
BalancerMember \"http://192.168.1.50:80\"
BalancerMember \"http://192.168.1.51:80\"
</Proxy>
ProxyPass \"/\" \"http://192.168.1.52:80\"
ProxyPassReverse \"/\" \"http://192.168.1.52:80\"
ProxyPass \"/test\" \"balancer://mycluster\"
ProxyPassReverse \"/test\" \"balancer://mycluster\"http {
upstream backend {
server 192.168.1.50;
server 192.168.1.51;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://192.168.1.52/;
}
location /test {
proxy_pass http://backend;
}
}
}위 코드는 웹서버로 들어온 요청을 로드밸런싱(분배 방식은 가중치 기반, 라운드 로빈 등으로 다양하다)한다. 이 과정은 L7 로드밸런서로서 작동하지만 L4(전송계층) 로드밸런서처럼 작동할 수도 있다(TCP 스트림 프록시 모듈을 사용하는 경우). L4 로드밸런서는 패킷을 복호화하지 않는다. 그렇기 때문에 L4 로드밸런서가 가지고 있는 정보는 IP 주소, 포트번호, Mac 주소, 전송 프로토콜 등으로 제한적이며, 단순한 Round-Robin 방식으로 트래픽을 균등하게 라우팅한다. 그래서 매우 빠르다. 위의 Nginx, Apache 설정은 http 서버로 트래픽을 라우팅하고 있지만, MySQL 서버나 MQTT 브로커로 트래픽을 라우팅할 수도 있다. 또한 모듈을 설치한다는 전제 하에 패킷 복호화를 진행하지 않으므로 라우팅 속도도 향상된다. 즉 전송 계층, TCP/IP 레벨의 로드 밸런싱이 가능하다는 의미이며, 이는 웹 서버가 L4 로드밸런서의 특징을 가지고 있다고 판단할 수 있다. 다만 웹 서버는 기본적으로 L7 로드밸런서로서 작동하고, 패킷을 복호화하여 URL, 요청 헤더 등을 고려하여 라우팅하도록 설계되었다. 따라서 웹 서버는 L7 로드밸런서로서 동작하지만, 특정 조건 하에 L4 로드밸런서처럼 동작하는것도 가능하다고 할 수 있다.